
In 2006, a Nature paper identified a specific amyloid subtype, Aβ*56, as the molecular driver of memory loss in Alzheimer’s disease. The paper was cited over 2,300 times; drug programs followed its logic downstream. In 2022, a Science investigation found that the paper’s key images appeared to have been manipulated. For sixteen years, nobody could answer what should have been a straightforward question: how much of what we believe actually depends on this single result?
The reason is that the infrastructure to answer it does not exist. Citation graphs record who read what, but they cannot tell you what breaks when a paper breaks. Large language models flatten the same gap into a different form: the model holds a belief, the user receives a sentence, and the reasoning that connects them is inaccessible by construction. (We traced this structural failure in The Anatomy of Belief.)
We believe the deeper problem is not better synthesis or better search. It is that belief itself — the relationship between evidence and conclusion — needs to become a structured, traceable object. That requires a new unit of computation.
This post introduces that unit and traces a twenty-year scientific claim through it.
The Geometry of Belief
When a person weighs competing evidence — for instance, deciding whether a new drug is effective — they hold multiple considerations in mind simultaneously: how strong the trial was, whether it has been replicated, whether there are reasons for doubt. The result is not a binary yes or no but a position somewhere between confidence and skepticism, shaped by everything they have seen so far.
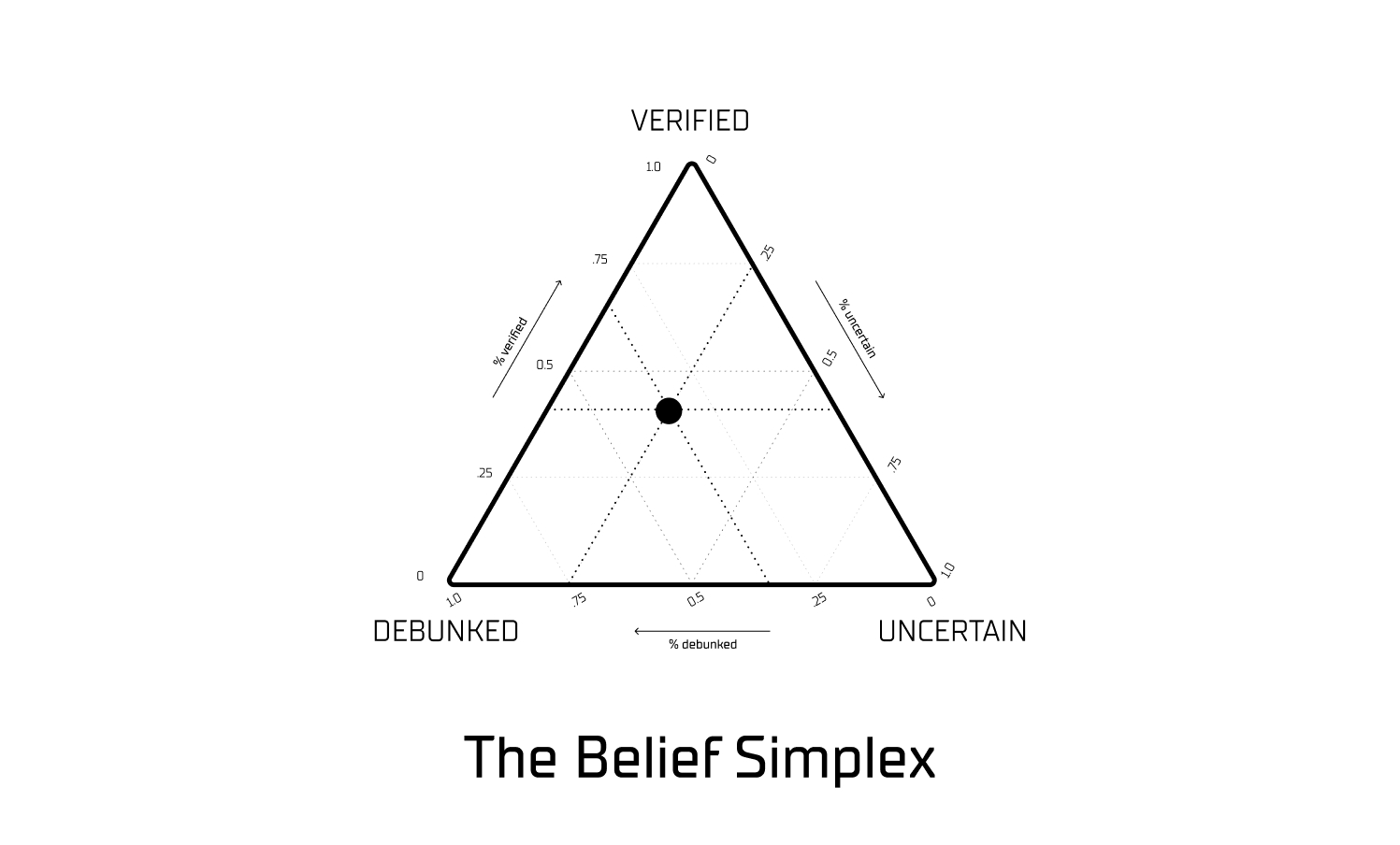
We can represent this process geometrically. Consider a triangle whose three corners represent pure states: Verified, Debunked, and Uncertain. Any position inside the triangle represents a mixture of those states. A claim near the Verified vertex has strong supporting evidence; a claim at the center is maximally uncertain. As new evidence arrives, the claim’s position moves, and the path it traces becomes the audit trail.
This geometric representation has empirical grounding. Shai et al. (2024) demonstrated that transformer models — i.e., the neural networks underlying modern language models — already represent belief states as coordinates in exactly this kind of structure, known in mathematics as a probability simplex1. The models build internal belief geometry whether or not anyone designed them to. We use the same mathematical structure but populate it with auditable evidence rather than opaque neural network weights. Where the model encodes belief in directions that cannot be inspected, the Epistron encodes belief in a coordinate space that can be read, traced, and revised.
An important constraint comes from Wang (2025), who showed that many standard threshold-based approaches to belief — i.e., rules like “if the probability exceeds 90%, treat it as true” — violate basic rationality norms2. These methods create discontinuities where small changes in evidence produce disproportionate jumps in conclusions. The Epistron avoids this by computing the closest rational position to the truth using a principled family of distance measures called Bregman divergences3, rather than comparing evidence against an arbitrary cutoff.
The triangle is the coordinate space. What we need next is the computational unit that operates inside it.
The Atomic Unit of Belief
Better search and better summarization will not solve this problem. The underlying issue is that scientific claims are treated as static text rather than as dynamic objects with traceable histories. Claims themselves need to become irreducible units of computation.
We call that unit the Epistron.
The Epistron is a versioned belief register — i.e., a computational object that maintains a complete ledger of every piece of evidence it has ever encountered, every assessment made, and every rule applied. It stores five things:
- The evidence ledger. An append-only log of every piece of evidence that has ever been associated with this claim. Nothing is overwritten; nothing is deleted. Each entry records what was observed, when, and from what source — producing a complete chronological record of the claim’s evidential basis.
- The policy bundle. The versioned rules that govern how evidence is scored and combined. When the rules change, the change itself is recorded, and the belief can be re-derived under either the old rules or the new ones.
- The belief coordinate. The current position in the simplex — not a binary label but a continuous coordinate that captures degrees of confidence across all three vertices simultaneously.
- The message vector. The signal this Epistron sends to other Epistrons that depend on it, encoding both what it believes and how confident it is in that belief.
- The provenance history. The full chain of changes: every time the belief moved, what caused it, and by how much.
The core design invariant is reproducibility: given the same evidence ledger and the same policy version, the Epistron always produces the same belief state.
Perceptron vs. Epistron
The closest precedent in computing is the perceptron — the foundational unit of neural networks, introduced by Frank Rosenblatt in 19584. The resemblance is structural rather than functional: a perceptron is a stateless function that produces an output and forgets; an Epistron is a stateful register that accumulates evidence over time.
| Perceptron | Epistron | |
|---|---|---|
| Stores | Weights | Evidence ledger + policy |
| Updates via | Gradient descent (training) | Event → re-project → commit delta |
| Output | A single number | Belief coordinate + delta + provenance |
| Composition | Layer-wise matrix multiplication | Dependency graph + typed message passing |
| Audit | Hard (opaque weights) | Native (every reason on record) |
A perceptron stores its reasons in numerical weights that are difficult to interpret after the fact. An Epistron stores its reasons as discrete evidence events — each one traceable to a specific paper, a specific dataset, a specific experimental result. This is what makes it possible to ask an Epistron why it believes what it believes and receive a legible answer.
When Epistrons are linked together — each one’s output feeding into others as input — the result is a Belief Graph: a dependency structure of belief registers passing typed messages to one another. The remainder of this post builds that graph, layer by layer.
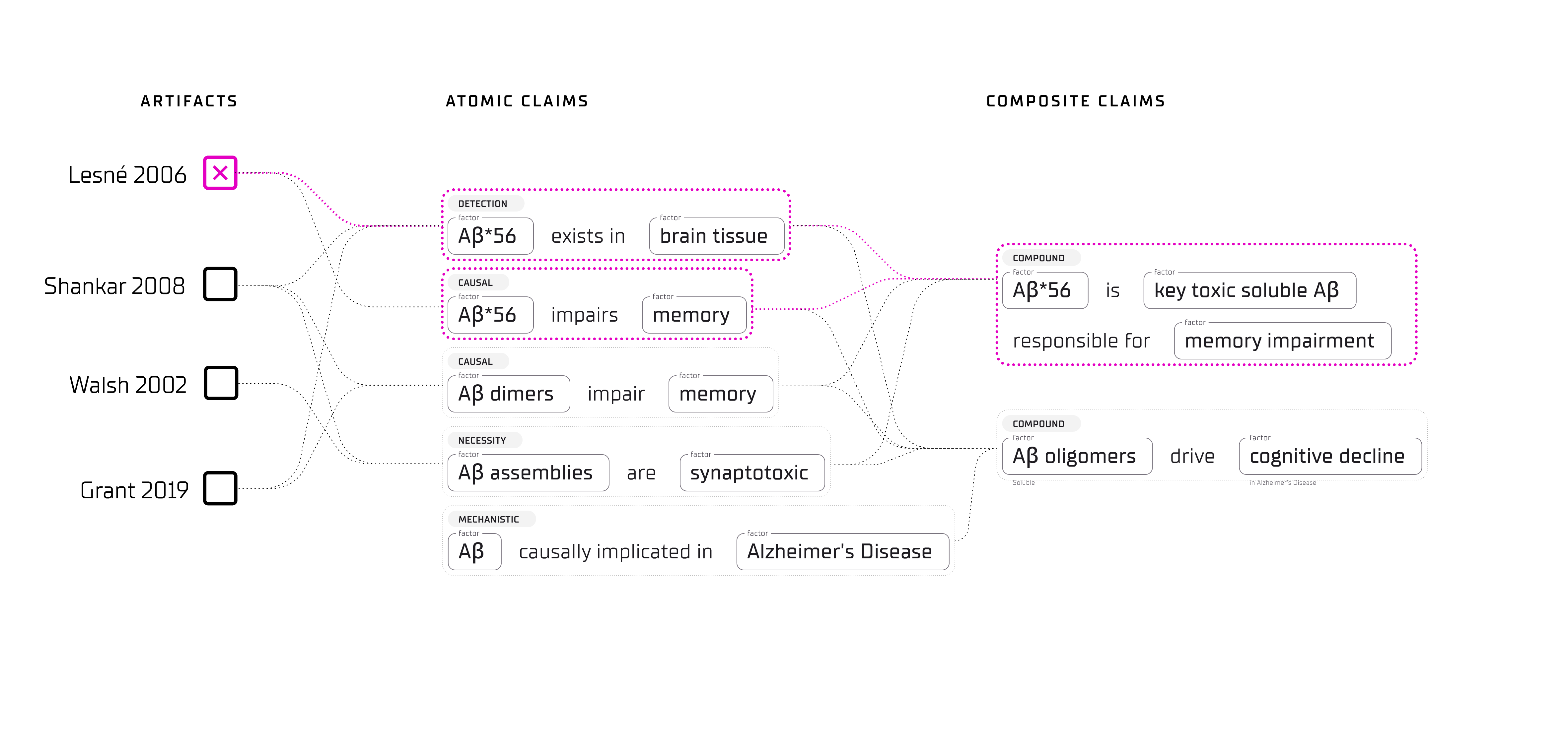
Aβ*56: From Cornerstone to Collapse
To make the architecture concrete, we return to the claim from the opening and trace it through twenty years of accumulating evidence. The interactive timeline below shows how the belief coordinate moves as each new piece of evidence arrives.
The claim: “Aβ*56 is the key toxic soluble Aβ assembly responsible for memory impairment.”
The prior isn’t blank
This claim doesn’t start from zero. Three established findings — that amyloid-beta drives Alzheimer’s, that soluble assemblies are toxic, and that cognitive decline precedes plaques — combine through a logistic bridge to give it a 73% starting probability. High, but not verified. The dot begins at pure uncertainty.
The cornerstone arrives
One Nature paper by Lesné et al. identifies Aβ*56 as the key toxic species. Three observations from a single lab push the posterior to 98.7%. Near-certainty from one source — the exact failure mode a dependency graph makes visible.
The cliff edge
Two events in nine months. A replication attempt fails to detect Aβ*56. Then Shankar et al. finds a competing toxic species — Aβ dimers — with strong independent evidence. The posterior collapses from 97% to 13%, the largest single reversal in the timeline. The parent hypothesis strengthens while the child claim breaks.
Peak conflict
New supportive data pushes back. The conflict score hits 0.91 — near-maximum disagreement. The evidence is actively fighting, not absent. The belief point sits between Verified and Debunked, stretched by directional contradiction.
The substrate erodes
The story shifts from “does it replicate?” to “can the evidence be trusted?” Definition instability, assay artifacts, and antibody cross-reactivity degrade the reliability of the original measurements. The warrant gap opens to 47 percentage points �— five years before the retraction.
Partial replications, growing pressure
Some labs partially replicate the finding with independent protocols. But editor’s notes and institutional skepticism mount. The counterfactual line — where belief would sit without warrant damage — diverges sharply from the actual posterior.
The investigation lands
Science publishes forensic analysis of image manipulation across multiple Lesné publications. Senior researchers disclose long-standing replication failures. The posterior drops to 0.3%. The formal machinery catches up to what the infrastructure already showed.
Retraction — the anticlimax
Nature retracts the 2006 paper citing excessive image manipulation. The posterior moves by 0.001. The warrant layer had already priced in the damage. The retraction is a formality, not a revelation.
Rehabilitation attempts
New supportive data arrives from independent labs — small upward blips. But provenance damage is structural: a pattern-of-fraud event pushes back. End state: P(T=1) = 1.0%, conflict = 0.50, warrant gap = 0.77. Debunked, with residual uncertainty.
The trajectory reveals several patterns that existing scientific infrastructure cannot represent:
- Over-concentration on a single source. The pipeline makes this quantitatively visible: after just three observations from one lab, the system assigned near-total confidence (a belief strength of 0.987). A narrow claim should not become foundational on the basis of a single paper.
- Correlated evidence masquerading as replication. Without explicit tracking of shared lineage — i.e., whether studies come from the same lab, use the same datasets, or share authors — a cluster of related work can create the appearance of independent confirmation5.
- Methodological concerns as early warning. Experimental artifacts, definitional instability, and failures to replicate serve as leading indicators. By 2019, these concerns had accumulated to a warrant gap of −0.47 — a quantitative measure of the distance between claimed confidence and methodological support — five years before the formal retraction.
- Retractions arriving too late. Formal retractions appear only after the belief has already propagated through the literature. A belief ledger can represent a provenance break the moment it occurs and compute which downstream conclusions are affected.
- The retraction barely shifting the outcome. By the time of retraction, the accumulating evidence had already moved the belief toward debunking. The warrant gap stood at −0.62 at the moment of formal retraction.
- Early detection is possible. Under the Explorer lens — a less conservative evaluation policy — the system classified this claim as Debunked in September 2008, sixteen years before the formal retraction. The evidential signal was present; no existing system was designed to surface it.
Scores Are Beliefs
A natural question arises: who assigns the quality, relevance, and strength scores that feed into each Epistron? If humans assign them, the system cannot scale. If language models assign them, the opacity has simply moved one layer down.
This is perhaps the most important design decision in the architecture. The answer is that the same machinery used to audit claims is also used to audit the evidence itself.
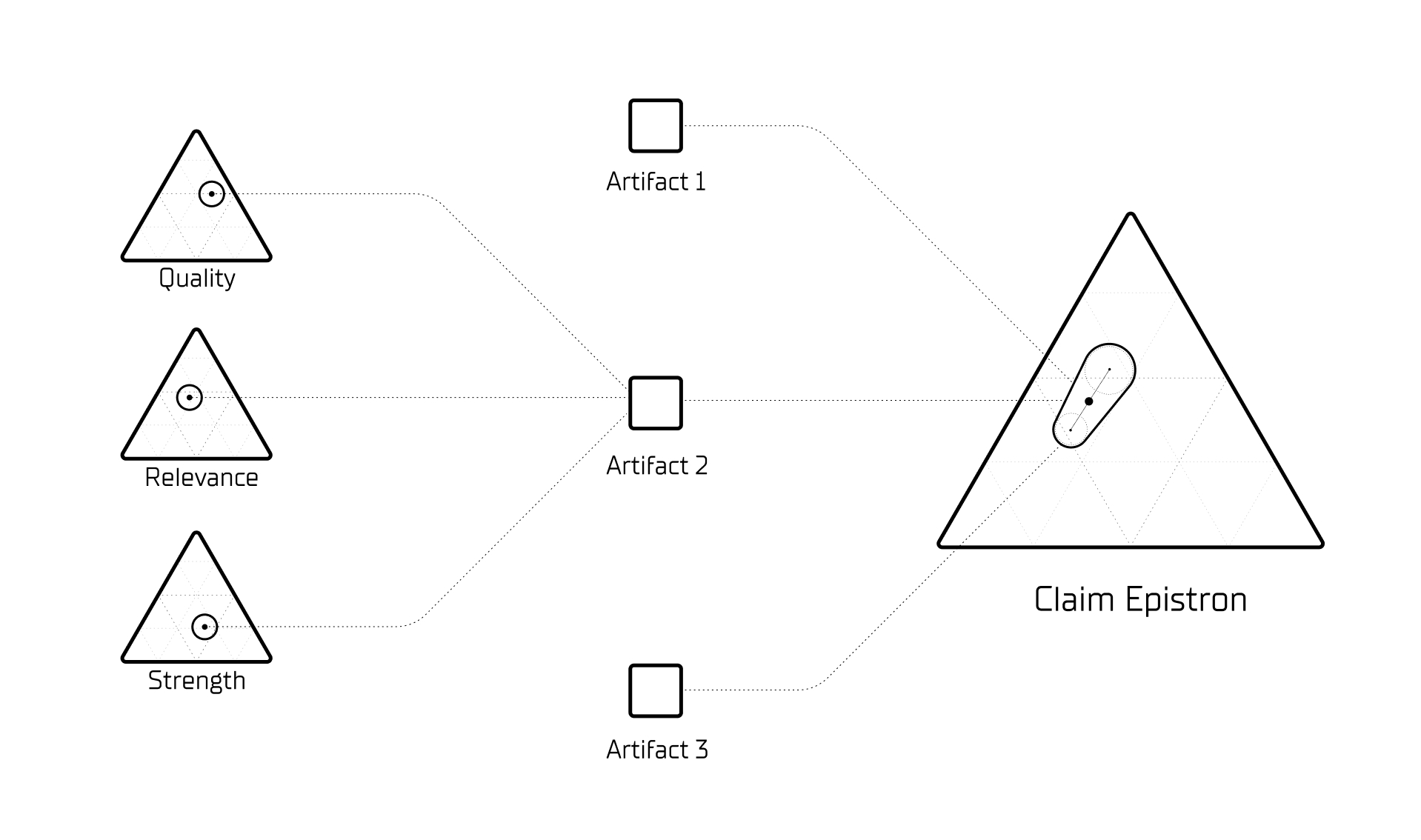
Every evidence artifact that enters the graph receives a cluster of assessment sub-Epistrons:
- A Quality Epistron evaluates whether a study’s methodology is sound. It takes in study-design features, reviewer assessments, risk-of-bias signals, and replication outcomes, then computes its own belief coordinate in its own simplex: {Sound, Flawed, Indeterminate}.
- A Relevance Epistron evaluates whether a study speaks to the specific claim in the specific context.
- A Strength Epistron evaluates the statistical and empirical signal.
Each sub-Epistron maintains its own evidence trail, its own confidence level, and its own provenance record. When reviewers disagree — for instance, whether a western blot band at 56 kDa represents a genuine Aβ assembly or a Protein A artifact, exactly the dispute Grant et al. raised — that disagreement is not silently averaged away. It manifests as increased uncertainty on the Quality sub-Epistron, which in turn weakens the paper’s contribution to the parent claim. Every evidence assessment is itself a first-class belief state, subject to the same audit trail as any scientific claim.
The current pipeline demonstrates this principle in practice. During calibration, the system learns how much weight to assign each assessment dimension from the evidence base itself: relevance receives a weight of 0.63, quality 0.22, and strength 0.15. The system discovered that whether a piece of evidence speaks to the specific claim matters roughly three times more than whether the evidence is generally high quality. This weighting was learned from the data, not imposed by design.
This recursive structure is what prevents the architecture from reintroducing, at the assessment layer, the same opacity it was designed to eliminate at the claim layer.
Claims Compose Like Software
The Epistron as described so far handles a single claim. But scientific questions are rarely single claims.
The statement “soluble amyloid oligomers drive cognitive decline in Alzheimer’s” is not atomic — it decomposes into smaller, independently testable assertions:
- “Aβ*56 impairs memory in vivo” — an atomic claim about a specific molecular species. The one we just traced.
- “Aβ*56 impairs memory in Tg2576 mice” — the same claim narrowed to a specific model system (a scoped claim).
- “Soluble Aβ oligomers drive cognitive decline” — a compound claim that holds only if at least one species-specific sub-claim holds and the bridging claim (“oligomer toxicity translates to human disease”) also holds.
When Lesné 2006 is retracted, the Aβ*56 atomic claim collapses. But the compound claim about oligomer toxicity survives — weakened but not destroyed — because Shankar et al. (2008) and Walsh et al. (2002) independently support the broader claim through a different molecular species7. The damage propagates precisely: it reaches the specific pillar that depended on the retracted work, but stops at the boundary of independent evidence.
This is the behavior a dependency graph should exhibit — localized impact assessment rather than wholesale collapse.
The Lens: Same Evidence, Different Policies
The walkthrough above presented the Lens as a display threshold — Explorer versus Skeptic. In practice, the Lens does something more fundamental: it configures which compositions are valid and how sub-claims relate to one another.
- Replication-Required Lens: Compound claims require independent lab replication for each atomic sub-claim.
- Mechanistic Lens: Allows animal-model claims to support mechanism hypotheses.
- Scope-Strict Lens: Only composes claims within matching model systems.
The same evidence graph, viewed through different Lenses, produces different claim structures with different dependency trees. The Lens is not a filter applied after the fact — it is a composition policy that determines what counts as adequate support for a given level of claim.
The Network: Three Layers
When enough Epistrons are composed, the Belief Graph takes on a layered structure:
- Layer 1 — Grounding. Raw evidence artifacts: papers, datasets, clinical trial reports. These are immutable once ingested, though they can be retracted or amended.
- Layer 2 — Projection. Atomic and scoped claims. Each is an Epistron computing a belief state from the Layer 1 evidence feeding into it.
- Layer 3 — Synthesis. Compound and higher-order claims. These Epistrons consume the belief states of other Epistrons — not raw evidence, but confidence-encoded messages from the layer below.
When a Layer 1 artifact is retracted, the change propagates upward: dependent atomic claims recompute their positions, and compound claims re-derive accordingly. This layered propagation is what makes the question “what breaks if this paper breaks?” answerable in seconds rather than years.
Conflict Is Not a Bug
Within this network, evidence can disagree — and the system is designed to hold that tension rather than resolve it prematurely.
When two papers flatly contradict each other, the Epistron does not force consensus. Both enter the graph with opposing directions: one pushes the belief coordinate toward Verified, the other toward Debunked. As conflict density rises, both signals are dampened, and the belief coordinate shifts toward the Uncertain vertex.
| Phase | Conflict | What's happening |
|---|---|---|
| Prior (2006) | 0.00 | No evidence — no conflict |
| Post-Lesné (2006) | 0.00 | All evidence agrees (pure support) |
| Post-replication friction (2008) | 0.41 | First disagreement enters |
| Post-Shankar (2008) | 0.69 | Strong bidirectional pull — support vs. competing species |
| 2011 (support + contradiction) | 0.91 | Peak conflict — evidence pulls in opposing directions |
| 2012–2019 (warrant attacks) | 0.84 → 0.54 | Conflict resolving toward debunking |
| 2025 (end-state) | 0.50 | Moderate — residual rehabilitation against dominant debunking |
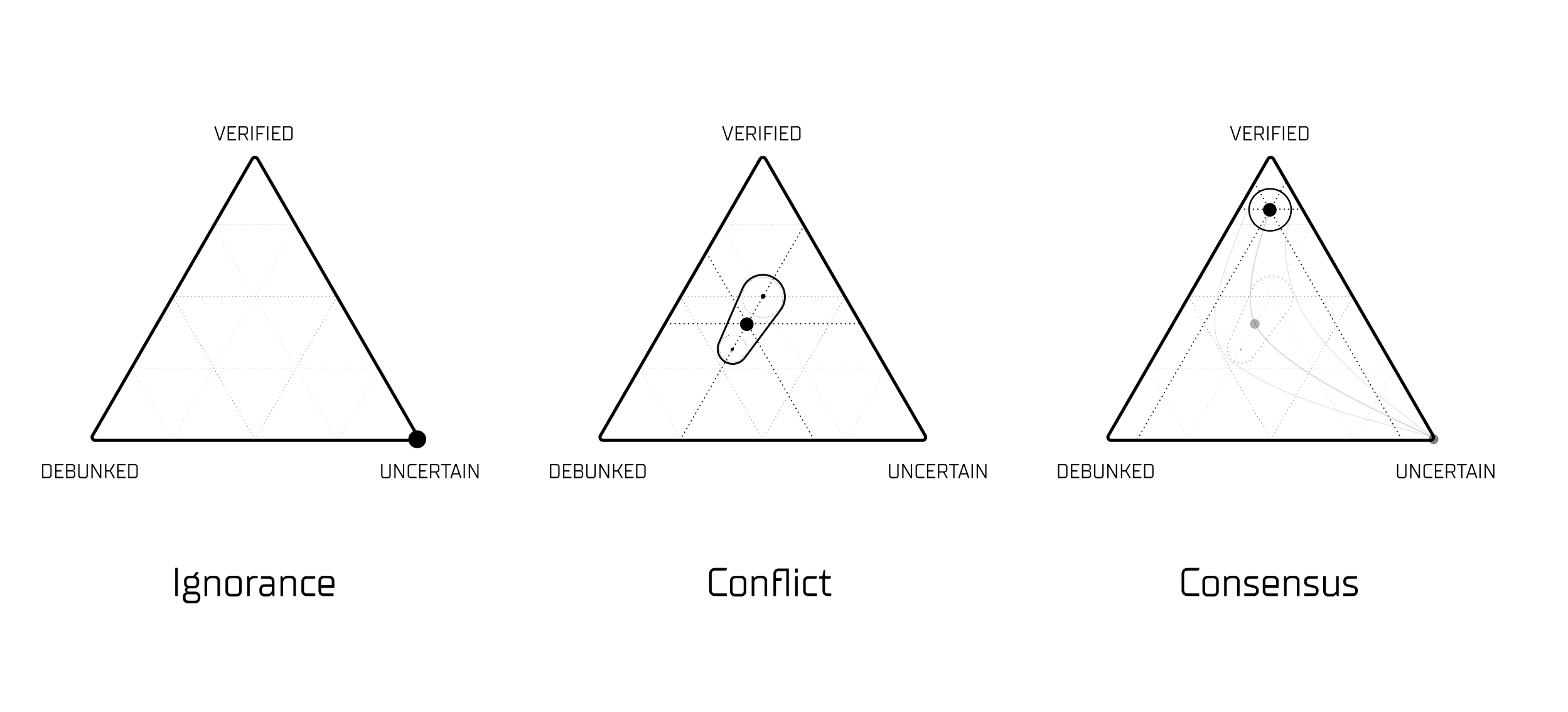
The important distinction is that conflict and ignorance look different in this system, even when the belief coordinate lands in a similar place:
- Ignorance: No evidence has arrived. The claim sits at the center of the simplex by default, not because the data is ambiguous but because there is no data at all.
- Conflict: Substantial evidence has arrived, but it disagrees. Eleven observations pull the claim in opposing directions; the resulting position near the center reflects genuine scientific disagreement.
- Consensus: Comparable amounts of evidence have arrived, and the direction is clear. Twenty observations and twelve provenance events converge toward Debunked.
A system that can only represent a single point in belief space — as most scoring and ranking systems do — cannot distinguish these three states. The Epistron can, because the signal between nodes encodes not just position but also confidence and the shape of the underlying evidence distribution.
The Interface
For human users, the Fylo interface is designed to function more like a research environment than a chatbot:
- Explore. An interactive topology of claims. Rather than scrolling through text, the user traverses a structured map of how claims relate to one another.
- Compare. Side-by-side evaluation of rival claims or competing interventions, with shared and divergent evidence made explicit.
- Replicate. A view that strips away narrative and exposes only the method, the data, and the expected outcomes.
- Audit. A chronological view of the belief state — how it evolved, what moved it, and when.
For machines, every Epistron is stateful and version-pinned. Claims become addressable computational objects rather than generated text strings. The same graph, queried at different times or under different policy versions, returns deterministic results.
Where both interfaces converge is the Resolver. Because the graph encodes where the unresolved conflicts are, it can generate what information theorists call a value-of-information agenda6: a ranked list of which experiment, if conducted, would resolve the most downstream uncertainty. The graph becomes not just a record of what is known, but a prioritized guide to what should be investigated next.
Scaling: A Package Manager for Knowledge
A single lab running a Belief Graph benefits from better epistemic hygiene. But the larger payoff comes when graphs connect across institutions.
Consider a concrete scenario: Lab A publishes a belief graph for GLP-1 receptor agonist outcomes. Lab B’s oncology graph imports Lab A’s GLP-1 graph as a dependency, because recent work suggests GLP-1 pathways may influence tumor metabolism. When Lab A retracts a study, Lab B’s graph receives the change automatically, and every dependent claim re-derives.
When merging belief states across labs, we do not force agreement. We perform a union with preserved dissent: import the claims, align the terminology using a shared relation schema, and preserve the divergence where it exists. Belief states become versioned dependencies — analogous to how software libraries track specific versions of their upstream packages. Downstream graphs reference a specific version of the upstream graph; when the upstream changes, the update propagates as a structured change event.
In 2006, Lesné et al. published a paper in Nature that became foundational for an entire research program. In 2022, its key images were found to have been manipulated. For sixteen years, no one could determine which downstream conclusions actually depended on which data, because no system existed to trace those dependencies.
The Epistron is the computational unit that makes this tractable. The Belief Graph is the dependency structure. The Lens is the policy layer. The Resolver converts the graph into a prioritized agenda for discovery. Every component — every score, every assessment, every composition rule — is auditable, reversible, and composable.
In the next post, we trace what happens when the graph’s own beliefs break, and how surprise propagates backward through the dependency structure.
Footnotes
- Shai et al., “Transformers Represent Belief State Geometry in their Residual Stream,” 2024. arXiv:2405.15943
- Mingming Wang, “Credence and belief: epistemic decision theory revisited,” Philosophical Studies, 2025. doi:10.1007/s11098-025-02321-z
- Lev Bregman, “The relaxation method of finding the common point of convex sets,” USSR Computational Mathematics and Mathematical Physics, 1967. doi:10.1016/0041-5553(67)90040-7
- Frank Rosenblatt, “The Perceptron: A probabilistic model for information storage and organization in the brain,” Psychological Review, 1958. doi:10.1037/h0042519
- Correlated evidence (studies from the same lab, shared datasets, overlapping author lists) violates the independence assumption behind naïve evidence combination. See Higgins & Thompson, “Quantifying heterogeneity in a meta-analysis,” Statistics in Medicine, 2002. doi:10.1002/sim.1186
- Ron Howard, “Information Value Theory,” IEEE Transactions on Systems Science and Cybernetics, 1966. doi:10.1109/TSSC.1966.300074
- Shankar et al., “Amyloid-β protein dimers isolated directly from Alzheimer’s brains impair synaptic plasticity and memory,” Nature Medicine, 2008. Nature Medicine. Walsh et al., “Naturally secreted oligomers of amyloid β protein potently inhibit hippocampal long-term potentiation in vivo,” Nature, 2002. europepmc.org