

The problem we’re staring at
Our collective signal-to-noise is broken. Humanity is producing more research than any single lab (or language model) can metabolize. The result: insights are entombed in PDFs, contradictions hide in footnotes, replication status is a rumor, and when findings change, updates do not flow through the system.
This is not a vibe. It is structural. Reproducibility lags in key fields1, retractions are rising and poorly propagated2, and the “more papers, more progress” flywheel is stalling.
Meanwhile, policy is about to flood the pipes. By December 31, 2025, all U.S. federally funded publications and their supporting data must be made immediately open3. Europe is locking in similar transparency with the EU AI Act4, which brings provenance and documentation obligations for higher-risk and general-purpose AI5.
FAIR data is not optional anymore; it is table stakes6.
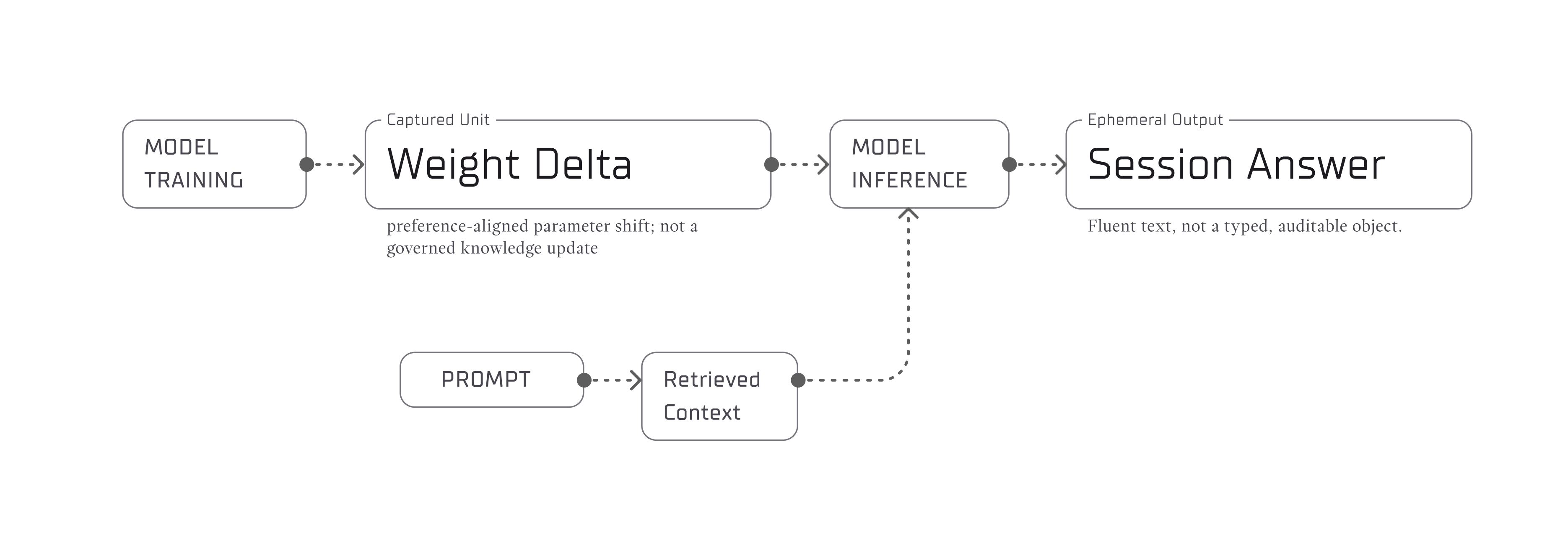
The current stack - PDFs on one side, black-box session-bound chat interfaces on the other - cannot carry this load. LLMs are astonishing writers, but without grounded structure they also synthesize convincing nonsense. Brittle pipelines do not heal with more sampling.
Why I care
This fracture wastes the scarcest resource we have: hard-won understanding. It slows cures and climate work; it erodes trust and rewards performative certainty over careful reasoning. I want a world where:
- Curiosity compounds.
- Disagreement is visible and productive.
- Machines amplify judgment, not overwhelm it.
What we’re building (and why it’s different)
Design north star: bridge how people think with how machines compute - without losing either.
Fylo is a living knowledge graph for science. We model how scientists already think: claims & evidence, not documents & downloads.
- Every claim linked to its evidence with line-level provenance.
- Arguments are first-class: supports / contradicts / replicates.
- Versioning is non-destructive: disagreement is preserved, not overwritten.
- Multiple epistemic lenses - consensus, skeptic, replication-only, meta-analysis - compile different views from the same graph deterministically.
- Governance flows from earned trust (transparent review queues, reputation ladders), not gatekeeper prestige.
Under the hood, Fylo is neuro-symbolic: we combine formal graph structure (for correctness and traceability) with learned semantics (for retrieval and cross-domain bridges). The literature agrees this hybrid is how you get interpretability and reasoning without giving up performance.
A simple mental model
Think of the research world as a garden, not a landfill.
- In the extractive model, papers are endpoints. Negative results disappear. Retractions do not cascade. We accumulate knowledge waste.
- In a regenerative model, everything is nutrient: contradictions update claim credences, failed experiments tighten priors, and verified replications water the most useful branches. Progress is not more nodes; it is better metabolism.
The data support the need for this shift. Disruptiveness in papers and patents has declined for decades7; “ideas are getting harder to find”, and drug discovery has long battled Eroom’s law. If the system’s marginal idea-yield is falling, then structure, not just scale, is the lever.
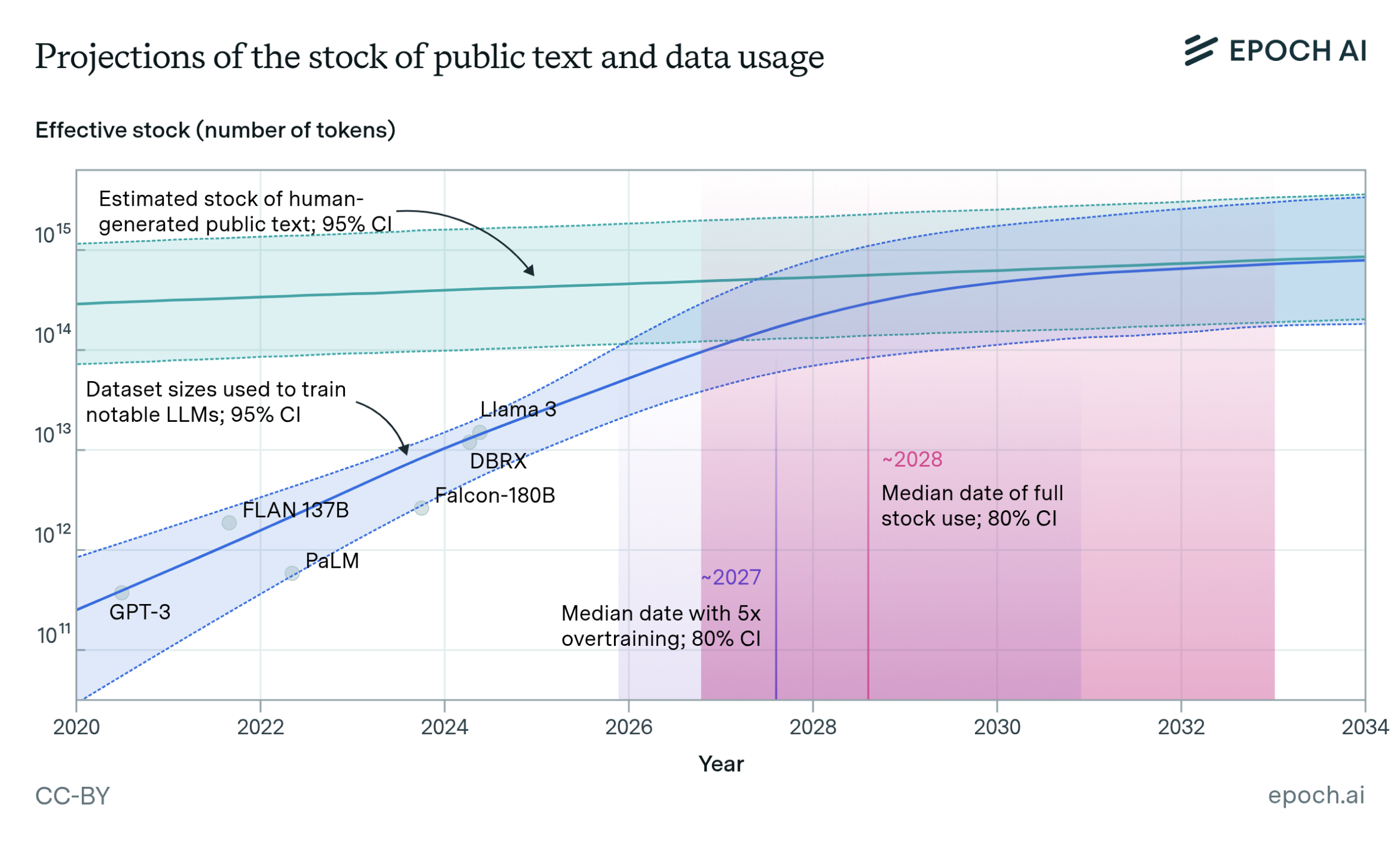
At the current rate, language models will fully utilize the human stock of public text and data between 2026 and 20328.
What changes on Day 1 with Fylo
- You can follow the evidence. Click a claim; see exactly what backs it, who replicated it, and where it conflicts. Retractions and corrections propagate because the edges carry the load.
- You can change the lens. Flip to replication-only before a high-stakes decision. Switch to skeptic to surface contradictions quickly. In a world of information glut, deterministic lenses beat vibes.
- You can reuse reasoning, not just results. Methods, datasets, and warrants - the reasoning that links evidence to a claim - are addressable parts, so cross-domain synthesis stops being artisanal.
The minimum viable philosophy
- Compose, then contend. First build the neutral scaffold of parts, so humans and machines can traverse it. Then lay arguments on top as supports/contradicts/replicates with weights. The scaffold is stable; the stances can change.
- Provenance over persuasion. Every claim resolves to exact lines, tables, or figures. Reasoning is a chain of atomic checks, not a single generative leap. If an input changes, affected edges update and the view recomputes.
- Metabolism, not accumulation. Surface duplicates and contradictions, route each to the highest-yield next step, and shed stale edges; promote what holds, split or retire what does not - so updates drive progress instead of piling up.
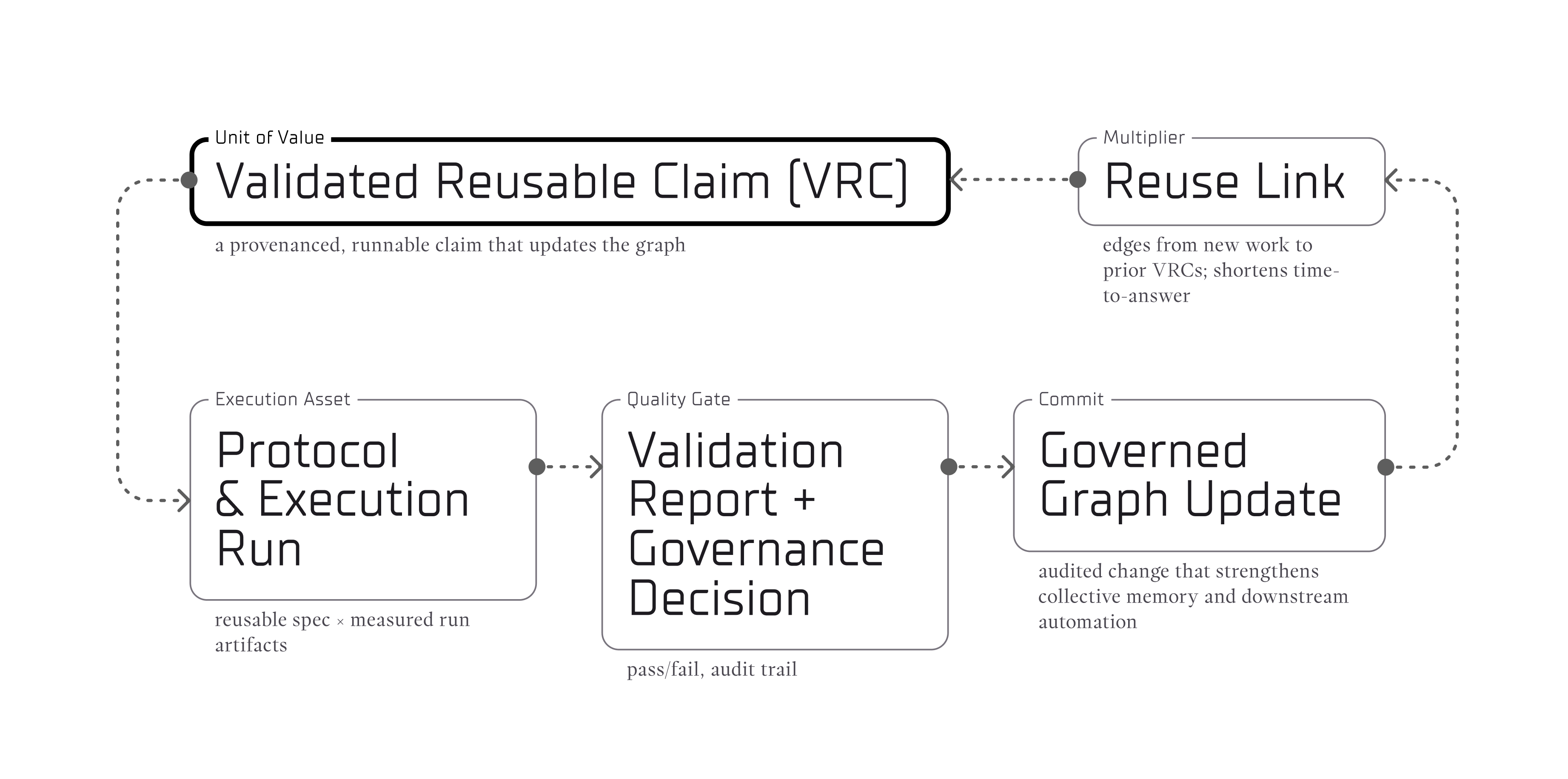
- Reuse first. The atomic unit is a validated, reusable claim (VRC). We reward reusing and resolving before adding mass. Track reuse, replications, contradictions closed, and energy per insight to keep incentives pointed at understanding.
- Open protocol, earned trust. Exchange claims via a shared schema, keep versioning non-destructive, run transparent review queues, and accrue topic-scoped reputation. Trust comes from auditable competence, not gatekeeper prestige.
What we measure
- Energy per Insight - GPU-hours per verified, accepted claim promoted into the graph. Goal: down-and-to-the-right as reuse climbs.
- Contradictions Resolved - percent of flagged conflicts that are closed, plus latency to resolution.
- Replication Weight - average independent replications per accepted claim.
- Knowledge Reuse Ratio - (# queries/generations that connect existing nodes) / (# new nodes).
- Regenerative Efficiency Index (REI) - composite: (verification x reuse) / energy.
These beat vanity stats like “total nodes.” A healthy system metabolizes; it does not just hoard.
Why now is the window
- Policy tailwinds: immediate OA by end-2025 in the U.S.; stricter AI provenance and transparency rolling out in the EU.
- Technical readiness: neuro-symbolic methods for reasoning over graphs are maturing; FAIR and modern KGs make machine-actionable science practical.
- Market pull: R&D leaders do not want more text - they want verifiable synthesis. (Also: hallucination risk and non-determinism are top-of-mind.)
What we’re building right now
- A hypergraph-native core for scientific relations with full context (method, dataset, warrant, scope).
- Provenance + versioning so every edit, branch, and merge is traceable.
- Epistemic lenses that compile deterministic views of a graph.
- A metalanguage for linear, isomorphic claim notation:
- so R&D labs, ELNs, LLM agents, robots, journals, and preprint servers can speak the same language.

What you can test now: check out FyloCore, our open-source real-time collaborative knowledge graph prototype.
How this becomes a movement
Open science already gave us the mandate (open by default) and the principles (FAIR). What is missing is the interface where openness becomes intelligibility - for humans and machines - at once. That is Fylo’s wedge.
If it works, knowledge stops decaying. Contradictions surface in minutes. Retractions cascade automatically. Replication-only views power high-stakes calls. Labs waste less and discover more. Doctors, policymakers, and engineers act with transparent evidence trails. Students learn from living maps, not static PDFs.
Curiosity compounds… and so does progress.
If this resonates, share it with one lab that’s drowning in PDFs - or one funder who wants decisions tied to transparent evidence trails. If you want to help stress-test the build, reach out and we’ll loop you into the pilot.
Sneak peek of Fylo’s interface

Footnotes
- Psychology’s 2015 mass-replication effort reproduced ~36–47% of effects, depending on metric. Claims need structures that surface uncertainty and let updates cascade.
- Retractions have exploded (e.g., >60k records in the Retraction Watch DB as of Oct 2025) and many papers keep getting cited post-retraction without acknowledgment — exactly the kind of failure that graph edges (not PDFs) can fix.
- OSTP’s 2022 memo requires agency policies to take effect by Dec 31, 2025; agencies posted implementation timelines in 2024. This makes machine-actionable provenance not nice-to-have but required.
- Transparency + documentation duties for general-purpose models are phasing in now. It raises the bar for traceable evidence.
- The EU AI Act is phasing in: initial bans took effect Feb 2025; GPAI transparency/documentation obligations begin Aug 2025; broader obligations apply into 2026–2027. That raises the bar for traceable evidence and model documentation.
- FAIR is explicitly about machine-actionable data and provenance, not just open access—which is why graphs (not PDFs) matter.
- Across ~25 M papers and ~3.9 M patents, the CD index drops steadily since the 1990s: more papers ≠ more breakthroughs. That argues for metabolism (structured synthesis) over mass.
- Multiple analyses forecast exhaustion of high-quality public text between 2026–2032 if trends continue. That shifts value from more text to better structure and reuse.